A few days ago, I was thinking about an old project that I have been thinking about for over two years now. I did not especially work on it, since I had a lack of motivation and skill.
Recently I came up with the idea that if I started softly then I could perform to do something valuable. So this article will focus on a problem that is part of my project: disassembling algorithms.
If you have a bit of acquaintance with the topic, then you should know at least there are two main algorithms used in order to
disassemble binary code:
- Linear Sweep: the most simple algorithm, since it takes a region and disassemble it sequentially, converting each byte it founds to an instruction, regardless of wether it really is an instruction or simply some data.
- Recursive Traversal: one more complex algorithm that consists in emulating the code, thus disassembling portions referenced by other instructions like (un)conditional jumps for example. One can distinguish code from data thanks to such an algorithm.
Therefore you may doubt that this post will focus on the last algorithm, because it is a bit more complicated that the first one. Moreover, you may found it in many known pieces of software, such as OllyDbg or, most commonly, IDA. There are also opensource tools that implement this algorithm, like the miasm framework.
There are several questions that might come up to your mind when you think about such an algorithm. For example, in intel x86 assembly language, given a region of code that is aimed to be disassembled for readability purpose, how would the algorithm behave when it reaches a conditional jump? What about an unconditional one? Do not forget the call & ret instructions as well!
When you meet such an instruction that references another memory address that is meant to be executed according to your context (I mean, register's values and flag's), you have to perform an analysis over it, even though you still have to disassemble further instructions at the current address if it's a conditional jump or a call.
In a nutshell, I came up with a hierarchy that structures the different kind of instructions that would help us perform
Recursive Traversal algorithm:
- Normal instruction: nothing to say about it, such instructions do not deal with direct memory references (exemple: xor eax, eax; mov eax,5 ; mov eax, [edx+4], etc.);
- Referencing instruction: contrary to a normal instruction, this one deals with direct memory address. It can be a branching instruction (call 0xdeadbeef) as an instruction that loads a value from an address (mov esi, [0xdeadbeef]). The last one could help us assuming that there is data at the given address, not code;
- Flow instruction: it is a referencing instruction that is likely to alter the program counter: jumps, calls, etc. So the referenced memory address obviously contains code;
- Hijack Flow instruction: I actually didn't find any best suitable term since English is not my first language, but I'm willing to think that it could be understandable: this last category covers unconditional jumps and ret instructions, since the next opcodes, if any, aren't especially meant to be executed.
With such instruction types, it is fairly possible to disassemble binary code - no matter from what instruction set they come from - with the recursive traversal algorithm. Indeed, you can assign a custom behavior to each instruction's category and record memory addresses to disassemble / reference in your region.
As we said earlier regarding this algorithm, the main goal is to distinguish code from data. By tracing through the code, we will be able to record much information.
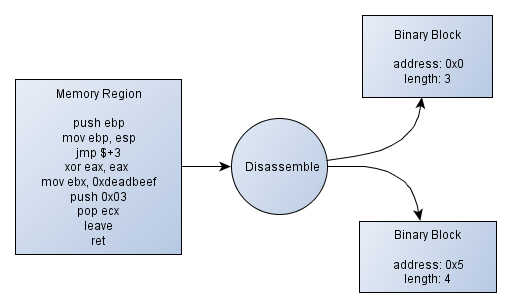
the miasm framework identifies the execution flow by identifying blocks of code and chaining them if there are branching instructions that tie them together. A block is made of a starting memory address and a length in bytes. Once you have these blocks into your memory region, you can assume that these will contain code and other non-referenced bytes would be data. This is not sufficient, but so far it is a good start. The figure 1 shows a diagram explaining how splitting code into memory regions could work.
Figure 1 - Splitting a code region into binary blocks
In this example, written in pseudo-code, we can see that there are a jmp
$+3 instruction, meaning in our case "jumps 3 instructions farther"
(whereas, in the intel instruction set, it means "jumps 3 bytes farther"). The instruction referenced by our jump would be "push 0x03". The other instructions "xor eax, eax" and "mov eax, 0xdeadbeef" are bypassed, thus not being referenced by any "binary block". It actually doesn't matter because there is no reason to execute this chunk of code.
To sum things up, still in our example, the first block goes from "push ebp" up to "jmp $+3", and contains 3 instructions (in a real case, the length would relate to the number of bytes, I guess you get it) and the second one goes from push 0x03 up to the last instruction - ret.
After having gathered all the information regarding the code blocks, it will be easy enough to disassemble code that is likely to be executed.
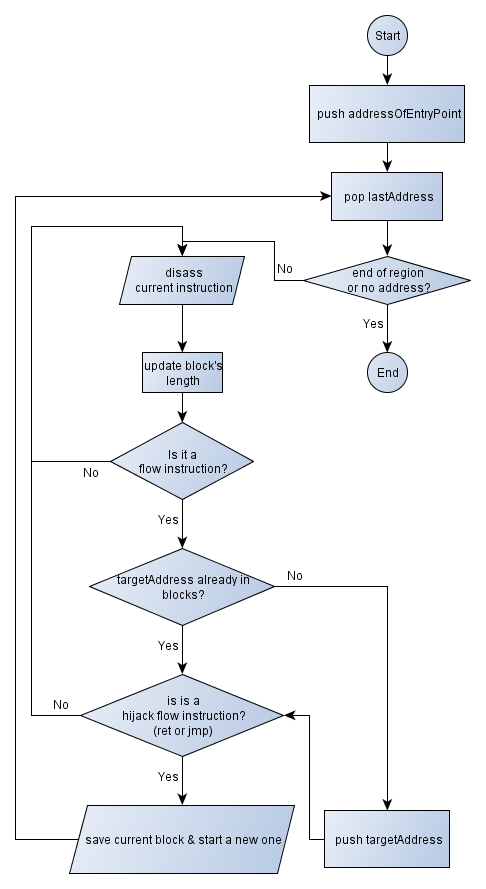
Now that we have a rough idea of what we could to, we could go on designing a simple flowchart explaining the Recursive Traversal algorithm. A few words to explain the steps...
We will maintain a stack of addresses to analyse, I mean, addresses that contain code, not data. The first address that will be pushed on to the stack will be the address of the program's entry point.
Then we enter a loop, popping the address at the top of the stack. Before disassembling the opcodes to get the desired instruction, several checks are performed. Indeed! Have we successfully popped an address? Is the address at the end of the memory region, meaning that there's not any opcode left to disassemble? That's the point!
If there are enough remaining opcodes, then we disassemble them, calculating the current instruction's length and memorizing it into a total sum. The total sum actually aims to be the block's length.
Things become interesting when we have a flow instruction (see the categories I suggested you above). If it is the case, then we have to push the target address into the stack for further disassembling if this address has not been analyzed yet (referenced by any existing block). And given the fact that it instruction hijacks the current flow (unconditional jump / ret) or not, we save the current binary block we are feeding and start a new one.
Since pictures are much more worthy than a long speech, let me show you the figure 2. It simply consists in the algorithm I just explained.
Figure 2 - Experimental Recursive Traversal flow chart
I'm willing to think that there are much better algorithms that mine. I actually didn't dig enough into smiasm code despite it is the only concrete example I have, but this article aimed to explain some way to understand how such an algorithm would work.
This could be the cornerstone for many projects, like a Reverse Engineering tool, simple disassembler or behaviour analyser. The ideas are not missing, just time!
Thanks for having read.
Ge0
References: